Published: Jun 18, 2023 by Simon Schneider
TLDR: With a modern cloud architecture it is possible to handle the data of more than two million bikes. The key components are RabbitMQ as MQTT broker, Kafka as event store and message queue and Elasticsearch as time series database. A microservice architecture allows to scale the cloud horizontally and to provide the services cost efficiently.
Introduction
Since 2020 I am working on a project for a company which is manufacturing e-bike components and providing a e-bike systems. The company manufactured over 2 million bikes which are used all over the world1. At the time the systems hardware consists of a motor, a battery and a display. While working there I had the chance to develop a cloud solution which provides the interfaces for multiple smartphone apps, IoT devices and other manufacturing related services. The cloud is currently handling the data of more than two million bikes and is growing rapidly. In this article I want to share the architecture of the cloud and the lessons learned.
A bike can be connected to the cloud via a smartphone app or via an IoT device. The smartphone app is used to configure the bike and to provide the user with information about the bike. The IoT device will give real time updates (e.g. battery level) even when the app is not connected to the bike and allows the user to control the bike remotely. The cloud is used to store the data of the bike and to provide the data to the smartphone app. Additionally data analysis is performed to improve the new and existing products. The stored data accumulates to multiple billion data points per year.
The architecture is still in development and will be improved in the future. Some parts of this architecture are already in production, but some are still in development.
Architecture
Requirements
The cloud architecture has to handle the incoming data from the bikes in real time and store it for later analysis. The main region in which the e-bikes are used is Europe, therefore then traffic is fluctuating during the day. Also the traffic varies during the week and the year. Because more people are using the bikes on the weekend and in summer. The cloud has to be able to handle the traffic peaks and to scale down during the night and winter. The master data for all bikes need to be stored in the cloud and has to be available for all other services. The telemetry data has to be stored indefinitely, while still being cost efficient. All telemetry data has to be available in near realtime (<1s), because can view this data from the smartphone app. Other departments are never allowed to access data directly, because the users consent is needed for data analysis. Only the data from users which gave their consent can be used for data analysis. Due to the amount of data it is not possible to pass a data dump to the data science department.
Overview
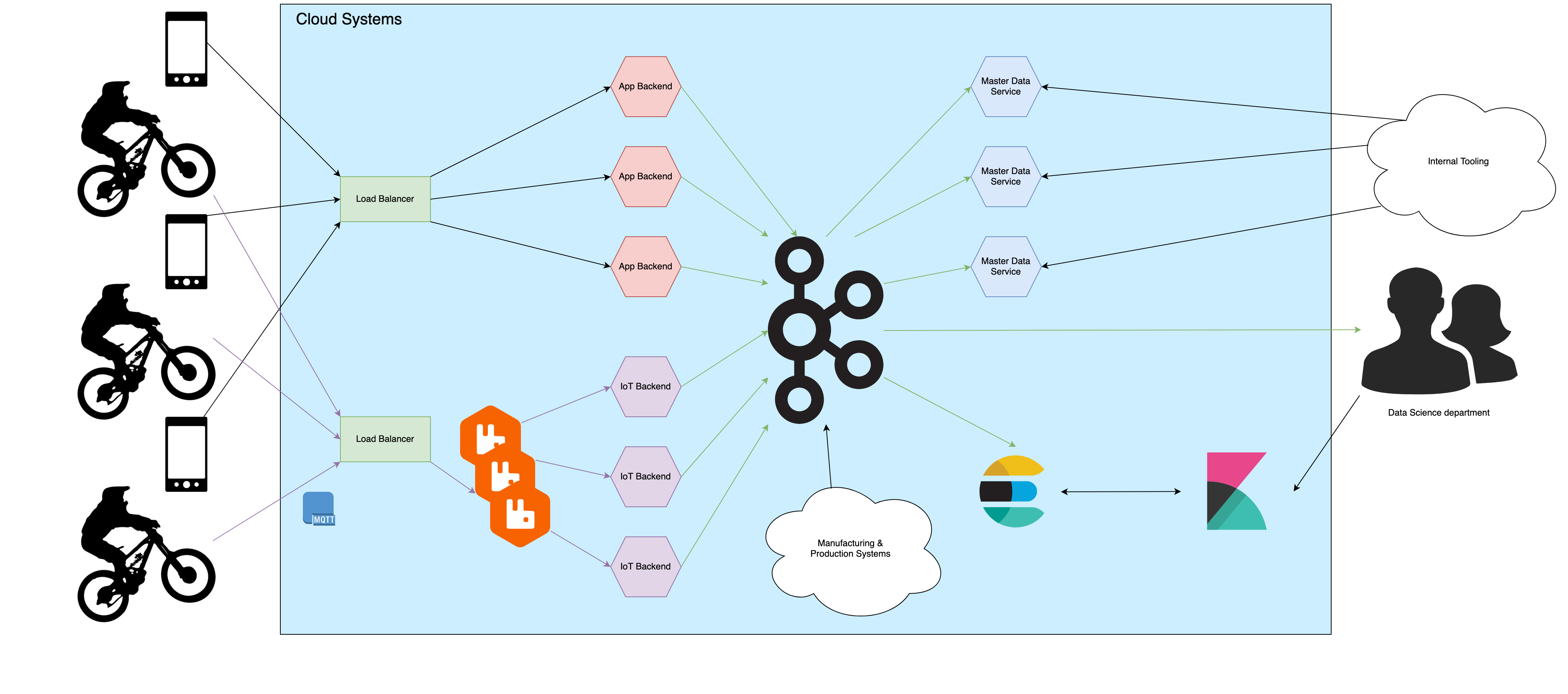
The overview diagram above shows how the data flows though the cloud systems. The systems shown in the cloud are just referenced in the following sections but not explained, therefore they can be thought of as a black box system. On the left side, the users with their bikes and smartphones are shown. Both connect to the clouds load balancer through the internet. The IoT devices of the bikes connect to the cloud via MQTTs. The smartphone apps connect to the cloud via HTTPs. The API services and the brokers are load balanced and high available. For the smartphone apps the data is processed in the app backend services. The messages stored on the RabbitMQ brokers are consumed by the IoT Backend. This service handles the messages and publishes the telemetry data to Kafka. All telemetry data is then consumed and stored in elasticsearch. The master data services stores the latest version of the telemetry data with the master data in its PostgreSQL database. The manufacturing and production systems also publish data to Kafka which is consumed by the master data service. These systems partly exist in the cloud environment and partly on premise, but are not shown in the diagram explicitly. The data science department consumes the telemetry data from Kafka or analyzes it via elasticsearch. The shows diagram is simplified and does not show all services and systems. There are validation and security processes in place which are not shown in the diagram.
Ingestion
Manufacturing Systems
During the manufacturing process, multiple systems are used to manage the production of the different components and the bikes itself. Most of the systems are legacy systems and are not able to communicate with the cloud directly. For the manufacturing of the bikes itself, the systems are used in the plants of the original equipment manufacturers (OEM). If the OEM is not using the production system correctly, it could happen, that the bike is not registered in the cloud and can not be used by the customer. This leads to enormous support efforts and costs. Therefore multiple measures were taken to ensure that the bikes are registered correctly. But the older data is still not reliable and sometimes has to be checked manually. Therefore the data from the manufacturing systems has to be cleaned up and checked for consistency, before it can be stored in the cloud. The process of improving the data quality is still ongoing and will be improved in the future. With the next hardware generation the data quality will be improved, because additional measures were taken, to ensure a bike is registered correctly and the manufacturing data is consistent.
Smartphone Apps
The smartphone apps are used to manage the bike and to provide the user with information about the bike. The user can record rides and navigate with the app. The collected data is enriched with the master data from the manufacturing systems and analyzed to improve the users experience with the bike. This allows to compensate for missing hardware capabilities, e.g. personalized range estimation. For the navigation a personalized duration estimation is used, which is based on the users riding behavior. These features are not possible with the embedded system because it has neither access to the navigation data nor to all of the users riding data. The cloud on the other hand can process all recorded data to provide these features.
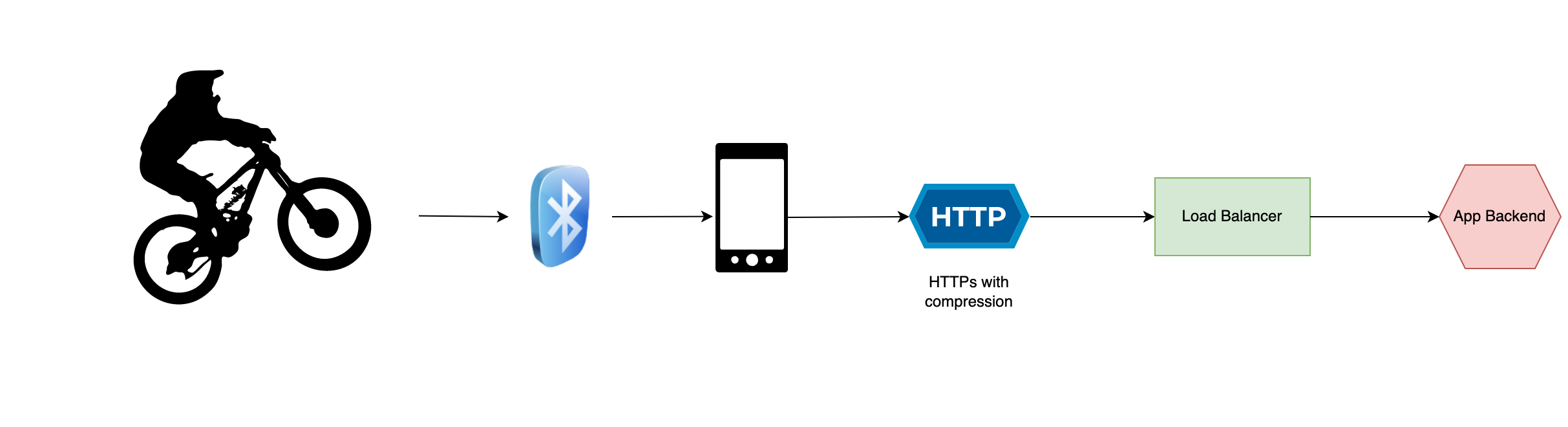
The smartphone apps are recording the riding data and send it to the cloud in batches. This reduced the battery consumption and allows for more efficient compression to be applied. The data is sent to the cloud via HTTPs and is published in a Kafka topic. The ingestion microservice is load balanced and can be scaled horizontally. This allows to handle traffic spikes while still being cost efficient during low traffic times.
IoT Devices
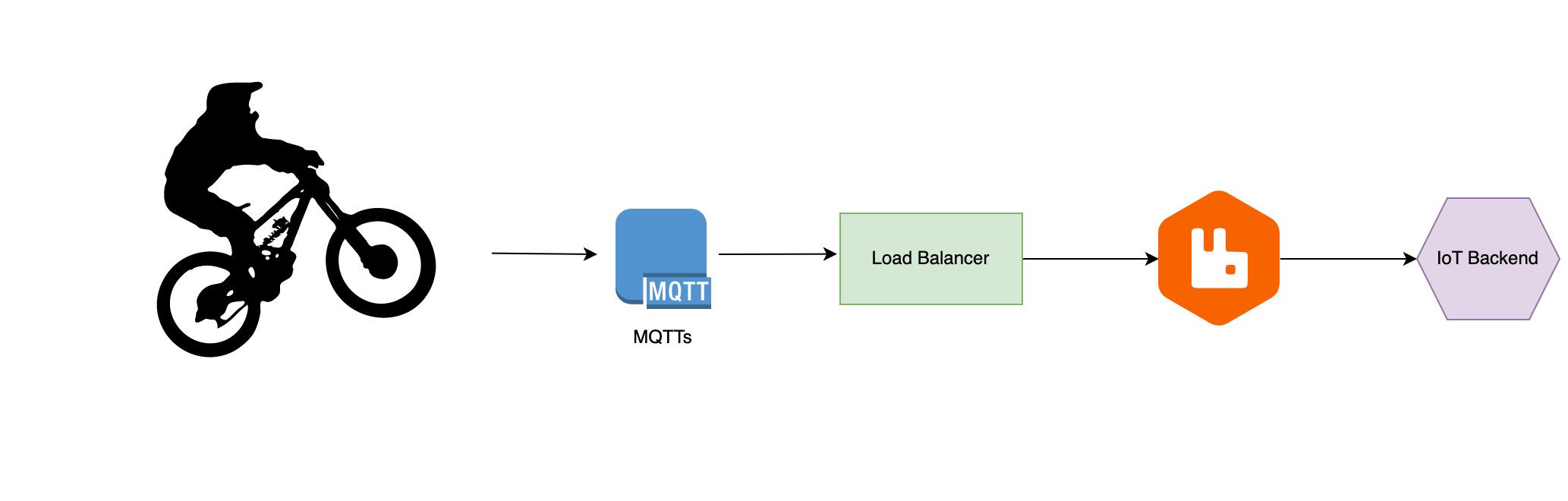
The IoT devices are used to provide real time updates to the user and to allow remote control of the bike. The devices connect to the cloud via MQTT. Each device is authorized by a client side certificate. The MQTT broker is configured to only allow connections from authorized devices. For the MQTT broker RabbitMQ is used, because it is easy to scale and provides persistence for AMQP messages. This is needed in case of a consumer outage. The messages are stored in a queue until the consumer is available again. Other MQTT brokers like Mosquitto do not provide this feature and would lead to data loss in case of a consumer outage. The RabbitMQ Broker can be scaled horizontally and is load balanced. The scaling is done by using different queues for different message types. Because the IoT devices are sending data all the time, the traffic is not fluctuating as much as the smartphone app traffic. The consumer microservice for the IoT devices reads and writes messages to AMQP topics. The telemetry messages are published to a Kafka topic. This microservice is can be scaled horizontally as needed, but in this case the bigger bottleneck is the broker itself. When a spike of messages is received, the broker has to store the messages in the queue. The consumer can then process the messages as fast as possible, but does not need to process all messages instantly. Dynamic scaling with RabbitMQ is not possible, because each queue has to be assigned to exactly one broker2. But high availability is more important than dynamic scaling in this case. Therefore the RabbitMQ cluster has to be scaled manually and the consumer microservice can be scaled dynamically.
Storage
Master Data
The master data is stored in a PostgreSQL database. This allows for fast access to the data and provides a relational data model. The data gets published to Kafka as a bike entity message. Additionally to the master data the latest telemetry data is stored in the database. Often only the latest version of the telemetry data is needed (e.g. odometer). This allows for fast access when displaying the data in the smartphone app or internal tools, while reducing the amount of data which has to be stored in PostgreSQL.
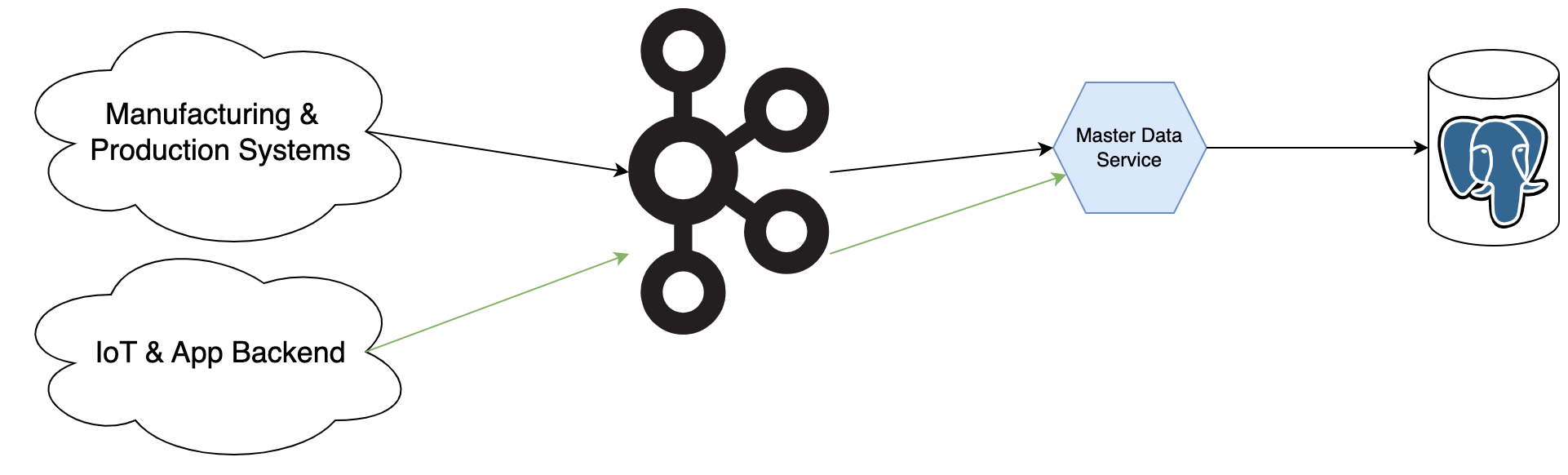
The master data does not only include bikes, but also individual components. This allows to track the components even when they are used in different bikes (e.g. batteries). During service components can be switched between bikes and then remanufactured or recycled. To keep track of the components it is essential to store the master data for the individual components as well.
The manufacturing data can be used in the data analysis to improve the manufacturing process. One analysis is to correlate production date and errors in the field. Only the connection between manufacturing and telemetry data allows for these kind of analysis.
Telemetry Data
The telemetry data written to Kafka is stored in Elasticsearch. This allows to store the data indefinitely and to query the data in near realtime. The data is stored in a time series data stream, which allows to query the data by time. The latest versions of Elasticsearch have a different data stream type for time series data3. It allows to to query the data faster and to store the data more efficiently. This comes with one major drawback: Data points can not be inserted after a specified time period has passed. This is a problem for the smartphone apps, because they are not always connected to the cloud and possibly send data with a delay of multiple days to months (e.g. last ride in november is uploaded in march when the app gets opened again). Since no data can be skipped / deleted, the data has to be stored in the older format, until a better solution gets developed.
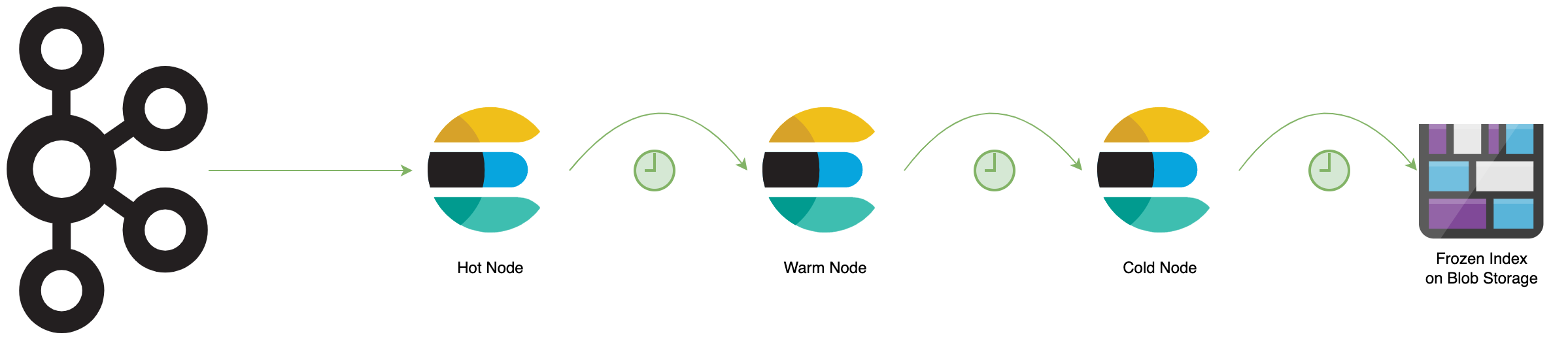
Because the data is stored indefinitely and the amount of data is growing rapidly, the index lifecycle management is needed4. Index lifecycle management allows to move data from hot to warm to cold storage. The hot storage is optimized for fast access and is used for the latest data. The warm storage is optimized for cost efficiency and is used for older data which is queried sometimes. The cold storage is optimized for long term storage and is used for the data which is old enough to be queried rarely. The Index lifecycle management is also explained in the talk “Zentrales Logging mit dem Elastic Stack”5.
Analysis
The data analysis is performed by a different department and is not part of the cloud. Therefore the data needs to get transferred to the data science department. Only the data from users which gave their consent can be used for data analysis. The direct access to the database is neither possible nor desired, since this would pose a security risk and would require a lot of effort to maintain. Therefore the data is transferred to the data science department via a Kafka topic. For analysis of historic data, Elasticsearch can be queried via the Kibana UI for ad-hoc analysis. The data science department can use the Kibana UI to query only the data from users which gave their consent. This was done by using document level security6 in Elasticsearch. Also the Kibana UI is security with hardware two factor authentication, rate limited and response size limited to ensure that the data can not be extracted in bulk.
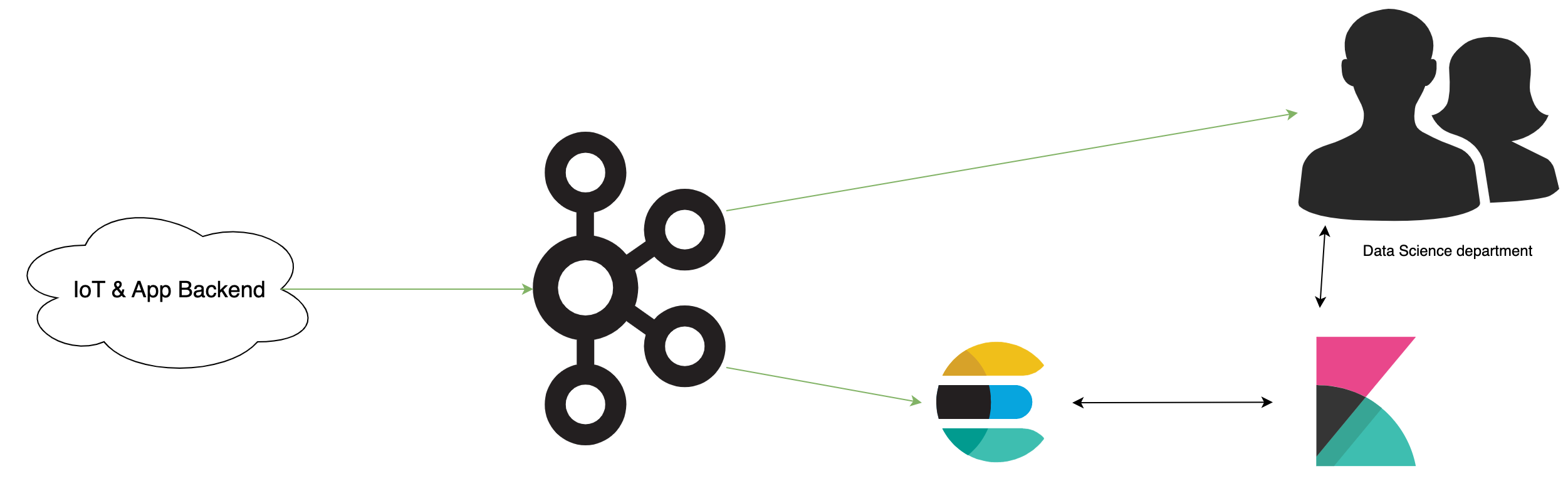
The amount of data in the Kafka topic is limited to a few days. This allows for real time analysis and stream analysis with Quix Streams7. Quix Streams is a python library for stream analysis. Instead of using a framework like Flink or writing a custom application on the JVM, Quix Streams allows to write stream analysis in python. Since python is often used for data analysis, this allows to reuse existing code and to reduce the effort for data analysis. Also machine learning models can be applied on the streamed data.
Lessons learned
Telemetry data storage
In the initial version of the cloud the telemetry data was stored in PostgreSQL. This lead to slow queries and complicated handling for dupplicated data. Data deduplication was done during index time, which slowed down the ingestion process. Additionally the data grew rapidly and the database had to be scaled up multiple times. The second iteration stored the telemetry data in Azure Blob Storage. This was a lot faster during indexing and allowed to store the data indefinitely. The main drawback was the slow query speed. All documents had to be downloaded and processed on the compute machine. This lead to slow queries and was not feasible for all use cases. The third iteration used Elasticsearch as a time series database. This allowed to query the data in near realtime and to store the data indefinitely. The costs were higher for the storage, but since less compute time was needed for the queries, and some other use cases could be implemented easier, the overall costs were lower.
Telemetry Ingestion from the Smartphone App
The initial version of the cloud used a REST API for the ingestion of the telemetry data from the smartphone app. The messages were batched and sent via HTTPs to the cloud. No limits on request body size or number of requests were set. This lead to a high battery consumption on the smartphone and to a high load on the cloud. The second iteration used a little bit different approach. The data was still be send over HTTPs, but the request body size was limited. Also the number of requests per IP was limited. This reduced the load on the cloud, but still lead to a high battery consumption on the smartphone and additional errors when the limits were reached. To fix the errors when the limits were reached the app had to check if the internet connection is sufficient to send the data. If the connection was not sufficient, the data had to be stored locally and sent later. This lead to a lot of additional complexity in the app but solved the problem when riding in regions without mobile connectivity. The third iteration used GZIP and Brottli for compression. The app sends the data in batches and compresses the data before sending it to the cloud. This reduced the battery consumption and the traffic send to the cloud.
Do not trust data you did not generate yourself
The data from the mobile apps is not always reliable. When the app is sending the collected data it uses the current time as timestamp. But since the user can modify the time on the smartphone, the timestamp can be wrong. This lead to a lot of problems when the data should be stored. Sometimes the data was stored in the future and sometimes in the past. This lead to a lot of problems when querying the data.
Additionally the data from the manufacturing systems is not always reliable. It can happen that multiple components with the same serial number are registered in the system. This leads to problems when these components are used in different bikes, because logically the component can only be in one bike at a time. Therefore always validate the data before using it. Inconsistencies in master data can lead to a lot of problems later on. This can be one of the reasons an SRE has to debug production at 3am, and as a developer you want your SREs to sleep well and be happy.
Not everything is scalable
For the initial data analysis the data was transferred to the data science department as a compressed NDJSON8 file. The file contained the data from all users which gave their consent for data analysis. This worked well for the first few months, but then the data grew too big to be decompressed on a single machine. The data science department had to batch the data and process it in multiple steps. This process was complicated and error prone, since all batches needed to be created correctly in the cloud, and the data science department had to process all the batches in order. The new solution with Kafka allows to process the data in near realtime and to scale the data analysis horizontally, when necessary.
References
Images
The header image comes from Andhika Soreng on Unsplash.
The social card image comes from Adrien Vajas on Unsplash.
The diagrams contains images from:
- Wikimedia Downhill_sketch
- Wikimedia PostgreSQL Logo
- Wikimedia Kafka Logo
- RabbitMQ Logo
- Elasticsearch Logo
- Kibana Logo
Citations
-
Press release Two million e-bike drives ↩
-
RabbitMQ Cluster Sizing and Other Considerations ↩
-
Elasticsearch Time series data stream ↩
-
Elasticsearch Index lifecycle management ↩
-
Simon Schneider, Zentrales logging mit dem Elastic Stack ↩
-
Elasticsearch Document level security ↩
-
Quix.io QuixStreams ↩

{kind=link}
{kind=link}
{kind=link}
{kind=link}